What Is Data Engineering: A Road Map to Success

Looking for a Career in Data Engineering?
Love data? Love learning how to collect and process it at scale? Neither do I. Just kidding!
But if you’re thinking of becoming a data engineer, it’s a solid choice.
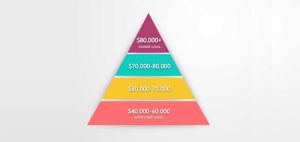
In fact, it’s one of the highest-paying jobs in tech today with an average salary of $123,000 for senior data engineers. Show me the money!
Today, we’ll unveil the art and science of data engineering.
What Does a Data Engineer Do?
Think of data engineers as the ones who build bridges between different business functions.
Data engineers are like the architects of data. They’re the data automators who fetch and transform data.
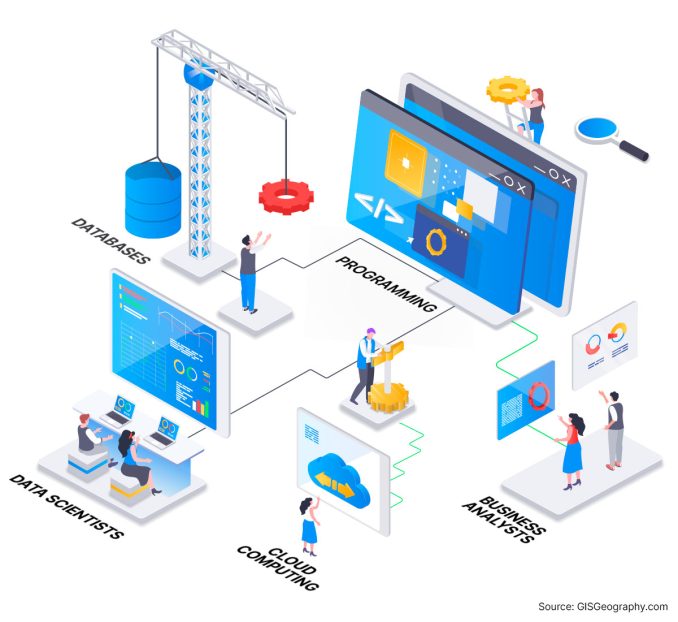
As you can see in the diagram above, they handle and organize information so that mainly data scientists and BI analysts can analyze it.
Data engineers ensure data flows smoothly, just like architects plan a house before builders bring it to life.
Show Me the Money!
Data engineers are one of the highest-paying jobs in tech today with an average salary of $123,000.
And salaries are only getting higher. Check out this graph with salaries year over the year.
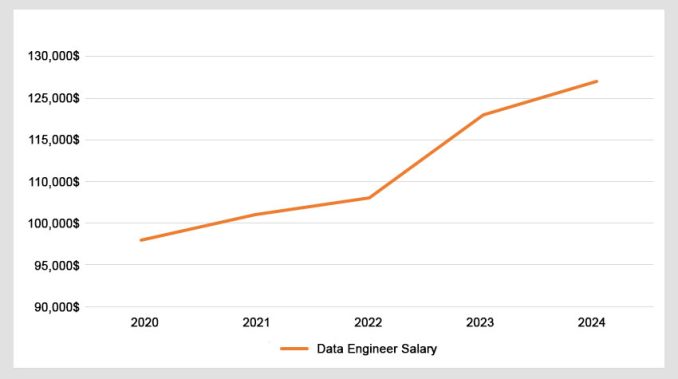
I wouldn’t call it a hockey curve graph. But what can I say that things are looking good for data engineers as a career.
You wanna know why data engineers are willing to do monotonous work? They get paid so well!
Technical Skills
To be a great data engineer, you need to know how to handle data in different ways. Here are six key skills you need:
It’s also about soft skills like communicating, teamwork, and attention to detail. More on soft skills later.
ETL and Data Pipelines
The name of the game in data engineering is data pipelines. The main player is ETL (Extract, Transform, Load).
ETL consists of all the different steps that information travels. From its source to where it’s needed for analysis, data engineers move and QC data.
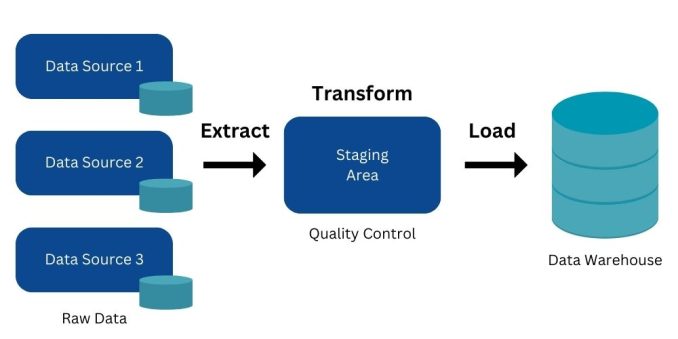
But it’s not just about fetching data. They are also responsible for ensuring data quality and reliability, especially for data engineering in GIS.
Data engineers also continuously monitor data pipelines and infrastructure. This can help resolve performance issues and ensure optimal data flow and storage.
Finally, they have to troubleshoot issues related to data quality, pipeline failures, and system performance. This requires a high level of problem-solving skills.
Data Warehousing
Imagine a data warehouse as a giant organized library for information. In data engineering, it’s like building and maintaining that library.
First, you collect data from different sources (books). Then, you clean and organize it (cataloging). Finally, you store it in a way that makes it easy to find and analyze (shelves and indexes).
Data engineers need to be familiar with data warehousing solutions like Amazon Redshift, Google BigQuery, or Snowflake.
The funny thing is that data engineers joke that it all ends up in Excel for the higher-ups. It’s funny because it’s true!
Schema Design
Think of schema design as planning the blueprint for a building. In data engineering, it’s creating a structure for your data.
You decide how information should be organized and connected. It’s just like deciding how Lego pieces fit together to build something awesome.

A well-designed schema makes it easy to store, retrieve, and understand data. Plus, it enhances overall system performance and facilitates seamless data integration across various platforms.
Data engineers design and implement data models that suit the specific needs of the organization. They also take into account the types of queries and analyses the end user will perform.
Soft Skills
Data engineers collaborate with data scientists (amongst others) to ensure that the data infrastructure supports the requirements of analytical models.
But it’s much more than just technical skills. Here are some of the soft skills you need:
It doesn’t take long to realize that you’ll need more than just technical skills to be successful as a data engineer.
Data Scientists vs Data Engineers
What’s the difference between a data scientist and a data engineer? The struggle between their roles is real.
When it comes to attention, all the focus is on the data scientist. Data engineers are mostly invisible to the executives. This is a good thing.
While it’s true that data engineers are “mostly in the background”… if I were to break up the different roles of a data engineer, I’d divide it like this:
| Characteristic | Data Engineer | Data Scientist |
| Primary Role | Designs, constructs, and maintains systems for data generation and processing. | Analyzes and interprets complex data to inform business decision-making. |
| Focus | Infrastructure, databases, and data pipelines. | Statistical analysis, machine learning, and modeling. |
| Tasks | SQL, Hadoop, Spark, Kafka, and data warehousing tools. | Predictive modeling, data analysis, algorithm development. |
| Tools | Python/R, machine learning frameworks (e.g., TensorFlow, scikit-learn), and statistical tools. | Strong statistical and analytical skills, and machine learning expertise. |
| Skill Emphasis | Strong programming and database skills. | Data-driven insights, predictive models, and actionable recommendations. |
| Output | Well-organized and accessible data infrastructure. | Building data pipelines, designing databases, and maintaining data infrastructure. |
| Goal | Ensure data availability, reliability, and accessibility for analysis. | Extract meaningful insights and knowledge from data to inform business decisions. |
| Collaboration | Collaborates with data scientists, analysts, and other stakeholders. | Collaborates with data engineers, domain experts, and business stakeholders. |
| Time Perspective | Concerned with the present and historical data. | Focuses on both historical data and future predictions, often with a forward-looking perspective. |
| Examples of Use Cases | Developing predictive models, conducting A/B testing, and optimizing business processes using data. | Developing predictive models, conducting A/B testing, optimizing business processes using data. |
But take this with a grain of salt. These are just general guidelines between these two data science roles.
And just to get this straight: Who owns data quality? Is it data analyst, data engineer, or data governance?
The better question is:
In some organizations, data governance doesn’t even exist! In some organizations, data engineers and analysts are the same guys!
Data Engineers Rarely Lose Sleep
Every data engineer I know loves that they fly under the radar. This is because it’s the end users or data scientists that attract all the attention.
Data engineers rarely lose sleep. But here are some of the nightmares that might wake them up:
But keep in mind… This is only for hardcore data engineers. Most forget about it all as soon as they leave the building.
Data Engineer Courses
You already know that data engineering is about using languages like Python for moving data. Your goal is to automate repetitive tasks in data management and processing.
If l were to do it all again, I’d take a course to fast-track my progress. I’ve enrolled in both of the platforms and I’d recommend them in the following order.
1. DataCamp’s Data Engineer Career Track
The Data Engineer Career Track by DataCamp is a gold mine for beginner data engineers. For instance, you’ll learn how to build your own data architecture for high-volume data processing.
This hands-on track will also teach you how to work with cloud and big data tools like AWS Boto, PySpark, Spark SQL, and MongoDB.
2. Dataquest’s Data Engineer Career Path
The Data Engineer Career Path by Dataquest will help you learn how to build data pipelines and use PostgreSQL for data engineering.
You’ll also learn how to analyze large sets of data using SQL queries. Develop the skills employers are looking for today in the field of data engineering.
Summary: An Intro to Data Engineering
To my data engineers:
The field of data engineering is dynamic. Professionals need to stay updated on emerging technologies. They also have to adapt to evolving data management practices.
Building systems that can scale with growing data volumes is a key aspect of data engineering. Also, data engineers design solutions that can handle increasing amounts of data without sacrificing performance.
Data engineering is becoming much more common in GIS. Just take a look at FME and the data engineering tools in ArcGIS Pro.
Do you want to be a data engineer? We want to hear from you. Please let us know about it in the comment section below.